Scrapy 运行 ImportError: No module named win32api 错误
Windows 系统上出现这个问题的解决需要安装 Py32Win 模块,但是直接通过官网链接装 exe 会出现几百个错误,更方便的做法是
1 | pip install pypiwin32 |
Windows 系统上出现这个问题的解决需要安装 Py32Win 模块,但是直接通过官网链接装 exe 会出现几百个错误,更方便的做法是
1 | pip install pypiwin32 |
最近做毕业设计,用Python写一个文本爬虫,我的目录结构是这样的:
1 | StockTextDigger |
当要从main.py中引用source_parser.py中的一个类时出现了“python ImportError: No module named source_parser”的错误。之前写过的Python从没出现过这样的问题,可是这次无论责骂么都解决不聊,无论是加上 __init__.py 还是sys.path.append(‘XXX’)都没有用,然后忽然意识到parser这个包很有可能已经在默认搜索路径中了,然后改名字,顺利解决。
又一个官逼同的典型例子[摊手]
最近心里一直很闷。
最早要从我关注hanser说起,一年前关注了hanser,之后取关,一个多月前又关注了回来。然后对她喜欢的一发不可收拾,去翻遍了她的微博,然后了解到了鬼叔——神威鬼鸣。
看过2012年B站的拜年祭,鬼叔相当于那个时期的B站元老,无限风光,是创世神一般的存在。就在前几天,鬼叔在微博上发布了长微博,说是自己生活压力其实非常大,九月份已经确诊了抑郁症,之后不会再在B站活动。(2021年8月最新更新:鬼叔的B站账号已经被封,理由大概是古早时期的《千本幼女》)
仅仅四年的时间,一个时代已经过去了,从hanser的关注者开始,我用人肉深搜扒出了一大堆上古时期的B站大神,已知最早的是09年到13年一直活跃的河童子,MAD周刊排行榜创始人。对于他来说,鬼叔都只是个后辈。这批元老现在都几乎不在B站活动了(当然可能是充实的生活让他们脱离了这个精神寄托,这里我们就事论事),有些还是因为和B站创始人徐逸发生了矛盾被打压而后离开的。有些离开的人在优酷投稿播放量是B站十倍以上。他们是真的爱这个地方。
看着这一切,这其实没什么大不了的一切,我却生出了一种深深的历史空洞感。一个时代过去了,人心一致的辉煌时代过去了,仅仅是几年的时间。那么放眼这数千年的历史,类似大大小小的历史进程已经上演了无数次,每次一定都让相关的人大发感慨,然而现在的我们连一朵水花都看不到了。
正当我感慨生不逢时之时,我忽然明白了原因:我怀念B站的上古时代,就像我上边提到的诸位大神怀念A站一样,都是在无条件地怀念过去,他们或许看着A站曾经辉煌的痕迹也曾发出过与我类似的感叹。
看看的如今的B站,真的那么不堪吗?不是的,厉害的新人越来越多,高质量的投稿也越来越多—虽然低质量的更多—大家也都找到了适合自己的商业模式,努力向前。我在怀念过去时选择性无视了这一点而已。“这是最好的时代,也是最坏的时代”,我多少能理解一点这句话的意思了,或许意思不对,就当我断章取义了吧。
我现在多少能体会为什么孔子他老人家一直推崇周礼,也能理解为什么现在的人动不动就说人心不古我当年如何如何云云。都是对过去的怀念和对现在的选择性无视罢了。时代确实在一直变得更好,即使有很多需要着力矫正的畸形的地方,也不会阻挡历史的趋势。
把握当下。这是一句轻飘飘的话,高中作文娴熟地运用了无数次,而个中真意非亲身经历不能理解。我不敢说自己理解了,但是要好过从前。对过去的怀念有时源于没有掌控住现在,现在的我就是这种情况,只要把握住了现在,那么未来就可以感慨现在的我是生得恰逢其时了。
很惊讶我竟然能说出这种高浓度鸡汤。我一直很讨厌这种动动嘴皮子就把一切客观条件和主观意愿都视作无物的心灵毒药。然而在经历了一些事情之后,自己的心境确实会发生变化,这的确是成长的过程。
就当作是复习之余的矫情牢骚吧。
待我回家,带我回家,代我回家
十年了,小哥说我如果没有忘,再回到这里还能见到他。如果小哥会从长白山出来,那墨脱的喇嘛每隔十年接待的客人又是谁呢?
我抽了一口烟,他妈的全都是胖子的汗臭味,比直接嚼烟叶还提神。“我说胖爷,小花就真的不下来看看吗?”,我看了看远处火光中时隐时现的青铜门,眼里闪过一丝黯然。胖子躺在碎石上,一边抠脚一边念叨,“只有真正的离开,才能真正的结束,真丫添堵,难道胖爷要交待在这?早知道我就好好当我的村支书了,你来见你的小情人,胖爷我来凑什么热闹啊”。
鬼玺跟小花在上边,不知道这青铜门到时间会不会自己打开,我身上穿着小哥留在外边的衣服,心说一开门看到小哥光着屁股在地上找衣服那乐子可就大了。可是如果看到小哥变成四阿公那样的僵尸也不是不可能,四阿公年纪大了,我还能用石头压住他,从鼻腔拿出钥匙,万一小哥变成僵尸,估计我还来不及把钥匙塞到鼻孔就被他扭断脖子了。我甩了甩头,强迫自己不去想这些东西。
正当我胡思乱想的时候,一边的胖子突然咋呼起来,“你他娘的敢揩胖爷的油!胖爷我砸死你个老不修!”,只见胖子一手拿着石头和一团什么东西扭打在一起,胖子一半是气的一半是吓的,手起石落砸的一下比一下狠,“哎呦卧槽你他娘还有尾……真他娘的邪性!天真你看看这个”,胖子说着把那“尾巴”揪下来扔了过来,然后就神色古怪地转过了头不再看我,我定睛一看只觉脑子轰的一声。胖子扔过来的是一把古金刀,这刀我只在一个人身上见过。我赶紧过去,原来胖子砸的是来时路上的阴兵,我凑上去看了下脸,虽然紫的发黑,眼睛也是一片死白,但是这脸怎么看怎么像……怎么看怎么像,小哥。
我坐在地上,脑子里嗡嗡直响,一片空白,就在这时,远处火光中的青铜门轰隆隆地响了起来……tbc
因为一些原因,现在暂时停止了Android的学习,转向JavaWeb的学习。说是这样,其实我不论哪一样都没有真的学得透彻,顶多算是个入门。因为现在仍然处于迷茫期,不知道在研究生阶段结束后(目前大三)到底直接出去搬砖还是再去国外深造。但不管怎么说,毕竟专业相关,这些东西还是掌握的越多越好。
JavaWeb 之前是接触过一点的,不过也限于做一个大作业网站的程度。现在开始从零开始一点点地做,把过程记录在这里,用作日后的备忘。
这个专题准备一直写下去,不过一年之内可能做不了太多东西,因为现在得忙考研的事情。现在开始后悔前几年没好好学习净捣鼓编程上的东西了,并不是后悔方向错了,而是后悔即使这样也没做出什么东西来,所以还是有一点虚度光阴的感觉。
各种各样的框架、设计模式层出不穷,其实搞得我挺烦的。明明就是某个场景下的某个解决方案而已,但是总是想搞得老子天下第一(技术无罪,框架开发者无罪,但是某些框架的某些不明事理的“狂热支持者”着实烦人)。当然,我现在是看源码都费劲,水平确实非常次。所以准备拿住一个框架开始琢磨,准备从 spring 开始,把 Data JPA、MVC、Security 什么的都先了解了再说,然后再决定下一步的路。
说实话确实挺迷茫的,这样下去自己根本没有竞争力,只是这样是绝对不够的,不过还是得从这里起步,至于是不是涉足安全、智能或者VR的领域,等研究生阶段再做定论。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
先大致说一下这两周完成的内容:
细节还有非常非常多,当然不是说要拘泥于细节而失去了整体意识,而是在细节的把控中了解整个项目的脉络。虽然功能远没有实现完,但是现在的项目结构已经略显臃肿了,所以下一周准备梳理一下整个项目,开始尝试自上而下地审视并重新设计一下整个结构。
本周做的工作值得细说的还是用户偏好算法的设计。用户偏好算法是我们项目的核心算法,目的是为推测出用户近期对于新闻类型的偏好,并记录在系统内,从而在之后可以让用户选择自己感兴趣的信息,并且每当发布了用户感兴趣的信息之后可以推送给用户。除此之外,最重要的一点是,系统可以根据用户的喜好向用户提供兴趣相投的好友,从而提升用户黏性,并可以隐形中推广应用。
作为一个用户偏好推测算法,可以划分到人工智能的领域,在这里我想谈一下对于算法起点的考虑。说到机器学习,普通水平的实现只要看了Coursera上吴恩达的Machine Learning就够用了(当然我是说非常简单的应用),再不然Github上一堆数千star的项目,甚至都不需要知道基本概念。但是在初版算法设计中我们并没有采用机器学习算法,这是由于以下几点考虑:
在初版算法设计中,我们只是使用了简单的权值计算,目前先实现这版测试一下效果如何,具体设计如下:
为推测出用户近期对于新闻类型的偏好,并记录在系统内,从而在之后可以让用户选择自己感兴趣的信息,并且每当发布了用户感兴趣的信息之后可以推送给用户。除此之外,最重要的一点是,系统可以根据用户的喜好向用户提供兴趣相投的好友,从而提升用户黏性,并可以隐形中推广应用。
算法计算结果是用户对于某种类型的新闻的偏好程度,目的在于两部分,第一部分是推测近期趋势,第二部分是推测用户喜好。
为了体现这两部分,我们使用两个衡量指标:时间因子 $tf$ (time factor)和认真程度 $cd$ (conscientious degree)来表示。为了突出两方面的因素,我们使用高阶运算来提升权值,计算出的值为 $tpw$ (temporary preference weight)。
除此之外,由于偏好值的计算是不断迭代的,所以每次计算新的偏好值时应该考虑之前的计算结果,给定一个权值因子 $wf$ (weight factor),并设旧的用户偏好值为opw(old preference weight),则新的用户偏好值为 $npw = opw \times wf + (1 – wf) \times tpw$, 目前取 $wf$ 为0.3,并取 $opw$ 初值为0。
把用户访问一篇新闻的时间以及在这篇新闻上的停留时间分别设为 $visitTime$ (单位:毫秒)和 $stayTime$ (单位:毫秒),考虑通过这两个因素来计算 $tf$ 和 $cd$。
我们在数据库中设置了一张用户偏好表用于记录用户偏好信息,表项有用户 $id$、新闻类型、偏好旧值和详细信息,在详细信息中记录了一个数组,数组中每一个元素都包含 $visitTime$ 和 $stayTime$ 两部分。
每当用户访问一篇新闻时,都会更新相应的表项。同时在用户表中添加一个喜好标签表项,记录用户最近最感兴趣的新闻类型,最多记录三个,太多的话匹配结果会过多,使得匹配系统没有了意义,而且用户也没有精力去关注那么多的新闻类型。当分别计算完一个用户对于各个新闻类型的喜好权值之后,将其排序,得到的前三名新闻类型放入喜好标签中。
当推送新闻时,直接根据标签过滤即可。推荐好友时,比对两人的喜好标签即可,只要有共同的标签就推荐,并且如果当前用户没有喜好标签,那么就随机从所有用户中抽取;如果当前用户有喜好标签,那么对于其他待匹配的没有喜好标签的用户而言,也采用随机抽取的办法。
关于用户喜好的计算时机,因为计算不是在服务器上完成的(用云引擎有点麻烦而且也没必要占用服务器资源),所以考虑只要用户登录了,就在后台计算用户偏好,每个登录周期偏好只计算一次。
目前为止只做了简单的试验,算法可以得到较为合理的偏好值,但是在真实的应用场景中效果如何还有待进一步的测试。
因为软件工程大作业要用网站作为手动添加内容的后台,所以向学校申请了一台服务器(WindowsServer 2008 64-bit)。因为不常用Windows的服务器,拿到手之后遇到了一系列问题,写在这里以备下次需要。
安装应用程序(WampServer2)提示系统缺失MSVCR110.dll
解决方案: 见百度经验。不吹不黑,百度就这点好,大众性的问题还是靠得住的。
WampServer图标一直是黄色,无法正常启动
测试了80端口和3306端口,都没有被占用,修改之后还是没有起作用。
解决方案: 想到wamp的安装是在MSVCR110.dll之前进行的,是不是有什么地方出了错误,所以重新装了一遍WampServer,问题解决。
服务器本地Locathost可以访问,但是在我电脑上通过公网IP无法访问网站,也不能ping通
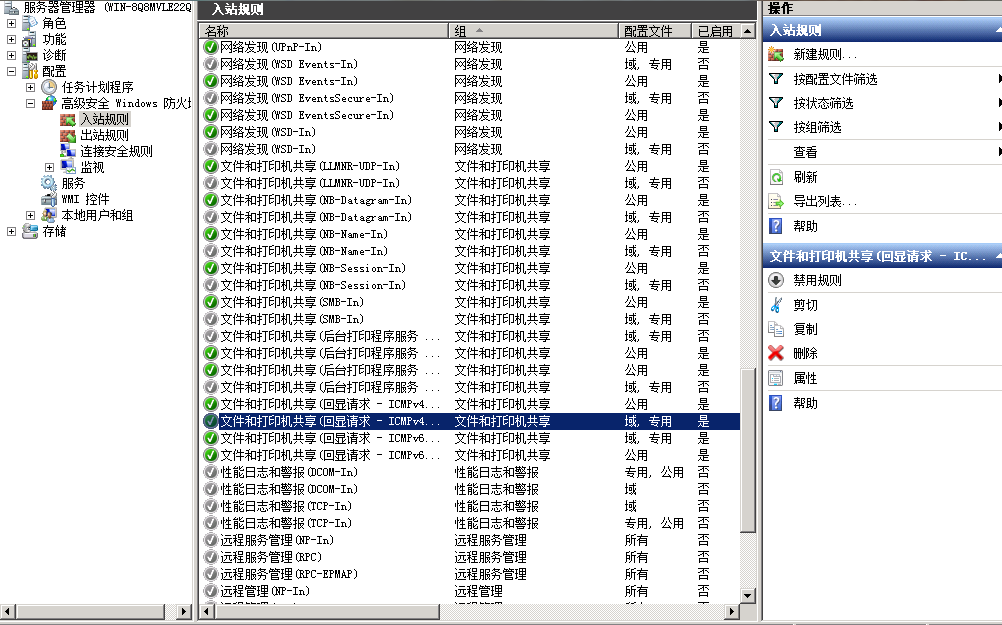
不能 ping 通问题的解决方案:打开服务器管理器->Windows防火墙->入站规则->文件和打印机共享(回显请求 – ICMPv4-In),启用。
不能通过公网IP访问网站问题
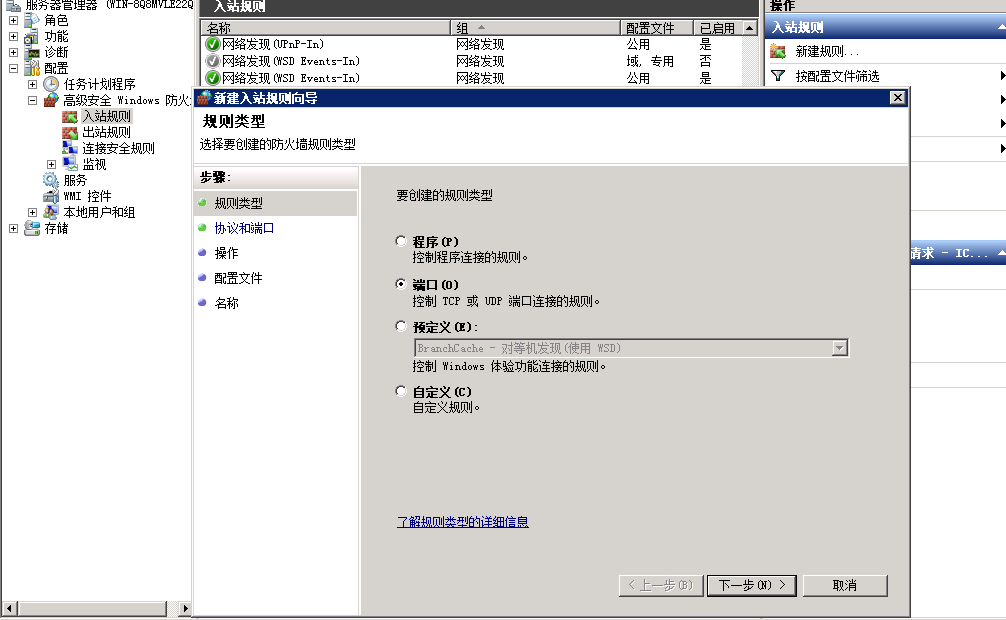
解决方案:打开服务器管理器->Windows防火墙->入站规则,新建一个端口规则,把80端口加上,随便命名,之后公网IP可以正常访问。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
终于开始了正式的开发工作。鉴于团队之前多少有点开发经验,很多界面写起来并没有什么阻滞,但由于我们都没有深入系统学习过Android架构和API,所以在有些细节上总是会有不到位的地方。
就拿笔者来说,虽然能照葫芦画瓢实现指定的界面和效果,但是总会在一些细微的地方卡住。如通过ViewPager实现SwipeView的解决方案中,ViewPager会时刻保留两个Fragment的View(此处存疑,只是实际操作的情况,并没有查阅过源码),其他的Fragment的view会被destroy掉。被destroyView的Fragment所有的控件都被“下架”,但是实例会被保留,那么对于EditText和RadioButton之类的控件而言,其内容是不会被保存的,除非单独设置变量保存或者放在savedInstanceState中。笔者在这里就卡了很久,又复习了一遍Activity和Fragment的生命周期,并且简单查看了一下ViewPager的源码,才解决了相关的问题。
在实现新闻列表的时候,由于需要上拂加载更多的效果,考虑现有开源方案太过庞大,所以笔者就手写了一个实现。因为新API强迫症,使用了RecyclerView而不是ListView。RecyclerView效率更高,功能更强大,操作也更灵活,但是少了诸多限制也就少了一些方便。如RecyclerView没有OnItemClickListener,笔者就往Adapter里扔了个回调,监听每个条目的点击事件。又如RecyclerView没有默认分隔线,这是可以理解的,因为要同时实现ListView、GridView以及瀑布流的效果。关于添加分割线的方案,鸿洋大大给出了一篇非常精彩的博文Android RecyclerView 使用完全解析 体验艺术般的控件 ,但是由于代码还是过多,所以笔者自己用代码模拟.9图片实现了分隔线效果,就过程而言要简洁的多(当然功能不够强大,具体见Android使用RecyclerView分隔线问题 )。
类似的问题还有很多,虽然都不算是大坑,但是有些地方还是挺绊脚的。现在尽量克制不去过于关注细节,先把大框架做出来,再进行优化工作。
贴出下一周的任务安排:
爵爷:
纪神:
小男孩:
老板:
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
本周大概把四个界面的样子做出来了(没有做细节,现在不贴图),并且老板那边的爬虫也可以跑了,虽然只是测试性入库,新闻的类别和学院学系等都还缠在一块没有分开,数据是不能用的,但效率可以满足要求,入库方案也并不难制定。
至此“试水阶段”结束,下边开始第一版最小化原型的开发(在倾物语(二)中已经提到,第一版最小化原型弱化设计,先走一遍流程知道我们在做什么,否则空谈设计很可能没有效果)。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
本周末我们组已经完成了《需求规格说明书》和《可行性分析报告》两份书面材料,具体内容见提交的文档。
这次想聊一下我们团队对于之后开发工作的构想。
就大的方面来说,我们在前端尽量使用现成的解决方案,并配合手写“胶水”,后端使用LeanCloud解决方案。
前端要展开有非常多的东西,因为Android的前端比HTML更加底层一点,要涉及的东西更多,考虑的面也更广,加之运行在移动平台,限制也颇多。
但是在参考现有解决方案(比如这个)以及基于我们之前的开发经验上,前端是可以跌跌撞撞地走的(当然是在不考虑外行的设计、咄咄逼人的PM、永不满足的客户的情况下)。
至于为什么不使用FB的react-native或是MUI等来做跨平台的界面,一是在性能上H5相对原生仍有不足,并且这一点在Android版本和手机性能差异极大的安卓市场上更为明显,二是一个移动端的应用无论干什么顶部都有一个小绿条咕咕咕地动在我们看来非常难受(纯个人观点)。因此我们考虑只在一些不重要的信息展示界面和时间上来不及的扩展功能上使用H5,其他情况仍然使用原生API开发。
还有就是 JetBrains(笔者免费IDE的提供商,因为有教育账号)的亲儿子 Kotlin,笔者没有深入了解,但是简单看了一下,第一感觉就是好玩,还没有感受到特别强大的地方(当然是了解非常不足),基于学习成本的考虑,我们还是使用了 Java 来作为主开发语言。
后端我们使用现成且强大的解决方案 LeanCloud。笔者多次被问到过“用LeanCloud这么简单方便甚至可以说是无脑的东西,还算是程序员吗?”。这种想法笔者之前也有过,但是如果不接受更快更好更方便的东西(并不是说LeanCloud就一定是这样,LeanCloud的适用场景其实限制还是蛮大的,这里不展开。但是相对于我们目前的开发需求,LeanCloud就是这样的),我们现在想用计算机还得在竹简上钻孔呢(笑)。另外笔者琢磨过算法,写过汇编优化的编译器(特别指明:最后什么都没做出来),也裸写过 socket 以及 RESTFUL,所以对于“不方便”的东西笔者多少还是有发表意见的权利的。出于学习目的或者对于要求特别严格的解决方案,唯有从底层慢慢写,但是就目前的场景来看使用 LeanCloud 是非常好的选择。应该针对不同的开发需求使用不同的方案,这就是我们使用 LeanCloud 的原因。
另外在开发上,我们目前的想法是先下手开始写代码,而不是先做细致的设计。因为目前团队整体的项目开发经验是不太够的,没有足够经验的支撑,一上来就做细致的设计很有可能会忽略了重要的东西而把精力放在了其实无足轻重的地方,而且做出的设计并不一定效果有多好(编者个人认为可以参考 Java 第一代 UI 库的设计)。当然先写代码并不是说“先写了代码再提取设计以完成任务”,而是先用粗糙的代码把流程简单走一遍,探探路上都有什么坑,然后再回头做设计,这样心里会踏实很多,设计结果也会更加可靠。这也是我们这个月的主要任务:做第一版最小化原型。
目前编者已经搭好了基于 Viewpager 的 Swipe View 以及 4 个 Fragment 作为主界面,下周先分工把这四个主界面按照原型设计做出来。然后依次跟进其他代码任务。下面是应用效果以及项目规模统计(是的我知道很丑,请不要再吐槽→_→)。