多线程的形象化理解
最近教大一的小孩理解多线程,想到了一个还算贴切的例子。
假设你要在12306上买两张票,假设票是连号发放的,那么当你一个人买的时候,买到的票一定是连号。而有时并不是连号的,这说明在你买票时也有另外的人在买,把本该属于你的连号票抢走了。
这就相当于多线程,每个买票的人都是一个线程,而总的火车票就是这些线程共享的资源。
最近教大一的小孩理解多线程,想到了一个还算贴切的例子。
假设你要在12306上买两张票,假设票是连号发放的,那么当你一个人买的时候,买到的票一定是连号。而有时并不是连号的,这说明在你买票时也有另外的人在买,把本该属于你的连号票抢走了。
这就相当于多线程,每个买票的人都是一个线程,而总的火车票就是这些线程共享的资源。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
本周六我们进行了一整个下午的详尽讨论,围绕以下几点进行了细致的分析,并且有了比较明晰的结论。
这是最早被提出的问题,但也可能是(不只是一个笨手笨脚的大作业,对于所有的项目都是)最难的一个问题之一。这几乎不涉及技术问题,而是需要外对于整体产品和用户市场、内对于项目定位的一个精准的把控。
由于条件的限制,我们并不能在这一点上花费太多的时间,我们认为基于我们实际情况的最佳的名字应该能够同时反映信息收集 + (基于共同关注点的)社交这两点,在头脑风暴中,我们想了很多正儿八经以及奇奇怪怪的名字。
最终我们比较中意的是“校园知事”,它满足了我们提出的两点基本要求,并且发音同“芝士”也让人多少有些亲切感(→_→ Fate第十职阶Eater)。暂定这个名字,只有有更好的想法再进行修改。
在定下了基本的思路与设计之后我们开始着手书面材料。第一步要做的就是《需求规格说明书》以及《可行性分析报告》。在《需求规格说明书》中我们将按照课件上的标准进行编写,并且对成员进行了分工,具体分工如下:
在《可行性分析报告》上,如果按照业界正式工程的格式来做的话会非常繁冗,并且其中涉及的市场背景、政策背景、法律背景以及资金链等对于我们目前来说有些不切实际,所以我们对于《可行性分析报告的规格》的格式进行了适应性调整。主要分为六个部分:
《可行性分析报告》将于《需求规格说明书》之后完成,届时将根据情况进行调整。预计最晚于下周末完成《需求规格说明书》和《可行性分析报告》这两份书面材料。
因为涉及人大身份(目前APP只覆盖人大范围)验证问题,我们需要微人大的开发者权限,并且在信息收集这方面如果能直接拿到各个学院的新闻API岂不美哉[王司徒脸]。
在微人大权限上,我们在微人大上申请了开发者账号,系统说7日之内会给回复,然而两个七日过去了······再等等,再催催好了,另外关于微人大的讨论中又催生出了一个问题:登录模式。是直接采用微人大账号登录还是新注册账号登录,再于APP中进行人大身份验证(就像进入APP后再进行邮箱验证一样)。经过讨论我们认为,如果使用微人大账号登录虽然直接方便,但是给人一种官方死板的气息(不吹不黑),且不利于之后用户群体的扩展(怎么能占领清华北大呢);使用独立账号注册 + 后期验证的方式虽然多了一步流程,但是让人感觉不受束缚(这种感觉很难描述),并且可以让用户先体验一部分功能,并有利于之后对清华北大的占领工作。
在各院新闻API获取这方面,我们以尽可能诚恳的语气向30多个学院发送了邮件,分析了共赢新性并询问是否能拿到新闻的接口,但截至目前没有任何学院给予回复(其实也难怪,人大黄页上找到的邮箱地址有好几个格式都是错的,还有几个要么没这个主机要么没这个用户)。我们并不准备就以上的经历来分析办事效率问题,因为很可能是我们的方法出了问题。目前看来用爬虫抓新闻是比较可行的选择,现阶段无法预料在爬虫部分将遇到的问题,我们将于下周写一份爬虫的demo,并连接LeanCloud进行测试。
这两部分是结合在一起做的,在简要功能的讨论中画出了主要的UI。我们不在这里贴出讨论过程中的草图,之后我们会用原型设计软件重新把图画一遍再发布。主要的界面就是新闻消息、 好友、发现(与自己关注点相同的人,了解自己最近的关注点或者查看自己的时间轴等等)以及更多(个人信息以及应用设置等)。虽然这是至关重要的一点,但是我们认为于”空想阶段“在这上面花费太多的时间不太合适,应该结合最小化原型设计出一个简略的功能框架,然后在做的过程中踩坑。
在这点上我们同样无法做出细致的估计,因为涉及公关处理、策略转型或团队配合等方方面面的问题,我们只是做了一个大阶段的预期。
总体来说我们目前的进度是可以接受的,在第一版的开发过程中一定会遇到非常多的问题,而且这些问题中有些将超出我们的预期与能力(即所谓的”坑“),我们会翔实地把这个过程中的心得体会记录下来,作为之后的一个宝贵的参考。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
上周我们在拿到问卷统计数据之后,就APP的初步设想进行了讨论。得到了以下结果:
手动添加信息,后台管理等
需要向各学院以及学校发邮件询问(包括各种新闻的API,以及微人大入口)
除此之外还有其他的一些细节问题。讨论完之后我们又对数据库每张表的内容进行了设计,得到了一个初步的数据库方案,并准备再次进行修改验证。详细的方案会放在之后正式的文档中。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
本周我们设计并回收了一套调查问卷,用以了解在校大学生对于学校各类信息的需求程度、了便利程度以及对于基于关注信息的应用的期待程度。最终回收结果部分摘录如下:
在刚刚结束不久的选课的过程中,您或身边的同学是否有询问过选课何时结束之类的问题?
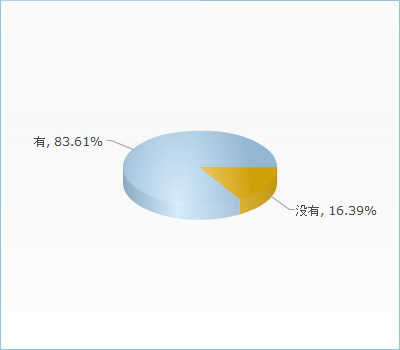
在刚刚结束不久的选课的过程中,您或身边的同学是否有询问过选课何时结束之类的问题?
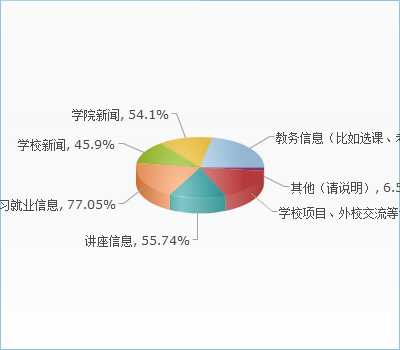
您觉得您获取消息及时吗?
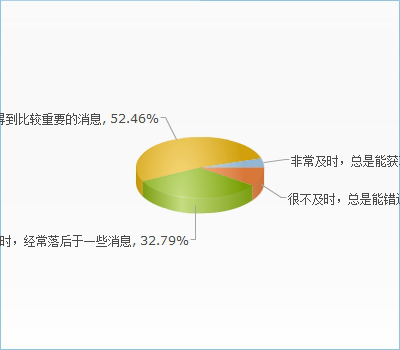
您获取消息的途径一般以什么为主?
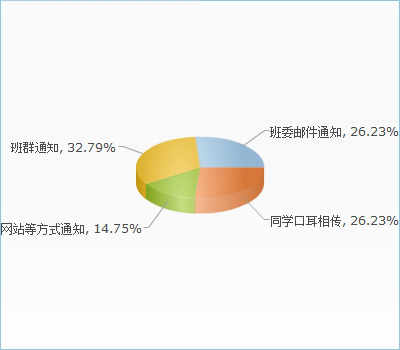
您是否使用校内新闻消息推送之类的APP?
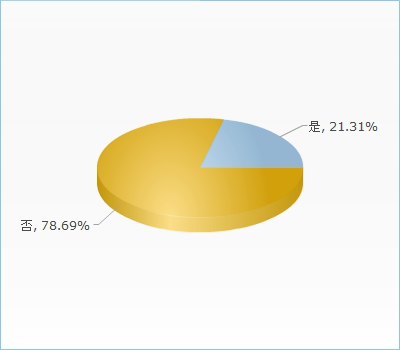
如果有人跟您关注相同的新闻,您是否愿意跟他(她)交流看法或互相分享信息?
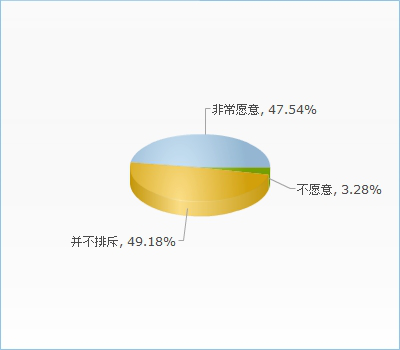
如果现在有一款推送校内信息的APP您有多大程度愿意使用?(1很愿意,5很不愿意)
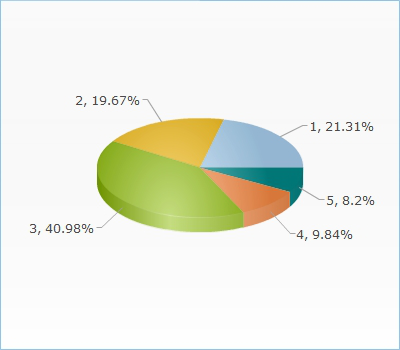
从主要的调查结果部分来看,能简要总结出以下几点关键信息:
以上是报告的部分内容,详细的分析报告我们会在《可行性分析》中给出。
从报告中可以看出我们目前的设想是基本可行的,下一步是尽快商讨最小化原型并收集用户评价,对现有轨道进行进一步的调整。
文章来源:中国软工亚洲指挥中心
共同作者:纪神,爵爷,老板,小男孩(按首字拼音排序)
责任编辑:爵爷
在组队初期,我们就达成了一致的意见:做一款为学生群体服务的Android平台上的应用。在前两周中,我们查访并使用了市面上很多流行的APP,并且尽力避免在用户和投资人眼中都基本上不再有希望的应用,如O2O类、基于IM的社交类应用等。
最终吸引我们注意力的是两款应用:今日头条和芥末校园。我们注意到这两款应用虽然用户量算不上特别巨大,但是在学生群体中有比较好的使用氛围,并且两者的方向也都非常受我们组成员的喜欢。
除了查找了大量的APP,我们还注意在身边查找潜在的需求。我们发现学生群体需求比较大的一点是校园中各种信息,如出国信息、保研信息、招聘信息以及其他各种各样的事情。虽然这些信息在校网站、院网站或者班长发来的邮件中都能找到,但是信息来源分散,而且相当一部分同学都没有按时查看校网站、院网站或者邮箱的习惯,所以这是不容忽视的一点需求。
我们经过调查,发现之前有不少人尝试过做类似的软件,比如社团宣讲信息、讲座信息的集成APP等,但都不温不火最终慢慢消失了。我们认为这是由于单纯的信息集成虽然满足了用户需求,但是没有也无法培养用户粘性,致使用户只是单纯的用来查过几次信息,之后就遗忘在了手机的某个角落。
综合以上种种,我们决定制作一款能满足学生群体对于信息集成的需求的软件,同时做需求上的纵向延伸,培养用户粘性,并且增加推荐率(用户向其他用户安利或者其他用户看到了相关的信息进而加入)。当前的打算是借鉴今日头条,通过用户查看的种种信息掌握用户目前阶段的关注点,再借鉴芥末校园通过这个关注点推荐和用户有相同或相似关注点的用户,通过社交来增加用户粘性。
我们也研究了《精益创业》中的很多说法,认为单纯自己去做设想或是“信仰之跃”是没有意义的,所以还是需要了解用户需要什么。因此我们下一步的目标就是尽快制作一份问卷,调查使用过类似软件的用户的看法,以及没有使用过类似软件的用户对于这个想法的意见和建议,进而修正目前的轨道。
自从Google推出了RecyclerView作为ListView功能更加强大的替代品之后,越来越多的APP开始使用这个控件。RecyclerView可以优化程序性能,并且由于功能上的高度解耦,可以无成本地在ListView、GridView以及瀑布流之间切换,但是也正因为如此,原来在ListView中理所当然的东西在RecyclerView中要自己来实现,比如分隔线,比如OnItemClickListener等(不是特别理解为什么Listener还要我们自己实现,我的做法就是往Adapter里扔回调)
说到分隔线,可以去实现RecyclerView.ItemDecoration来定制,在鸿洋大大的博客里有非常详细的讲解,按照这个来做其实也不麻烦,而且一次编写复用终生,但是我做的时候还是想偷懒,不想去写那么多代码,所以想用背景图片来实现分隔线效果。
我的RecyclerView中每个item的背景是这样的,用了selector实现点击前后的变色效果
1 |
|
其中@drawable/list_item_bg_pressed是这样
1 |
|
使用layer-list来实现效果:第一层使用分割线的颜色,并在底部padding一个窄边,第二层使用正常背景颜色,这样写而不是直接用一张图片代替的原因是:如果使用普通图片作为背景,当图片被拉伸时分隔线会明显变粗,效果非常不美观(当然.9图片没有问题,想了想还是直接用代码写了),而用代码就没有这个问题。这种效果我还用来实现一些输入框。
@drawable/list_item_bg_unpressed 同理,就是把第二层的颜色换了一下。
那么为什么不直接用一张图片来代替呢?因为有些情况下RecyclerView每个条目的高度并不是一样的,这样对于普通图片会产生纵向拉伸的效果,使得分隔线变得非常可怕,而用代码来实现的.9效果则不会有这个问题。
使用spring框架,自己组装了一个信息搭载类扔到JSP中渲染,大致是这样:
1 | UserBasicInfo userInfo = new UserBasicInfo(user); |
以及
1 | <img id="user_avatar" src="${userInfo.avatar}" class="img-responsive col-md-6" alt="用户头像"/> |
这时候运行时就会出现标题中的错误,UserBasicInfo是pojo,是放在UserController.java中的一个非public类。试过把他做成bean仍会有这个错误,之后考虑spring是使用代理来做这些事情的,默认访问权限的类spring可能访问不到,就把这个类单独做成一个文件做成public的,问题解决。
大作业,使用SpringMVC + Hibernate搭一个小网站,但是中途出现了这个问题,困扰了我一天时间。
是的这个问题很烦人,所以如果你已经尝试过:
仍然没有结果的话,那么你的问题应该就是
你丫是不是把数据库保留字当列名了,真以为SQL不是编程语言啊
血泪的教训,以上
对于一个作家,最重要的是能写出出色的文章,文章的水平如何,和作家用什么颜色、形状、粗细的笔来写没有任何关系。假如出现这么一幕场景:许多作家围坐在桌旁,口水飞溅地争论:
“英雄才是最好的笔!”
“瞎说!关勒铭才是最好的笔!”
“英雄笔在未来十年必将消亡的 10 个原因”
“新的写作模式,双手梅花篆字”
“怎么在一分钟之内写 300 个字——论英雄没有关勒铭流畅的原因”······
可以想象是个什么场景吗?
是的,我当然知道把程序员比做作家是牵强附会并不合适,但是一些(甚至可以说很多)程序员在讨论、在追求的都是用什么语言,用什么框架,有的人没有科班背景只是在培训机构培训了几个月(没有任何对培训机构偏见的意思)就出来加入了轰轰烈烈的”程序员讨论“中。
这样真的有意义吗?难道写代码真的要与语言、框架绑定在一起吗?你是学 Java 的,让你写 Python 你就可以说自己不是程序员了吗?程序员从何时开始这么廉价了?语言、框架(以及目前各种 Mxx 设计模式)对于程序员不就像笔对于作家一样只是工具而已吗?为什么作家要被笔束缚?为什么程序员要被语言、框架束缚?
程序员应该是骄傲的作家,不应该沦落为体力劳动者,如果你是后者,请不要,至少不要在我面前说你自己是个程序员!
最近在做JSP大作业,因为懒得写jdbc + 封装字段了,再加上也想学习一下SSH,就使用Hibernate来做持久化。但是中间遇到了中文乱码问题:
向数据库插入中文之后,在sqlbuddy看到的结果是乱码,已经确定乱码问题一定出在Hibernate向数据库插入的过程中。然而明明已经在前端、Servlet、数据库分别设置了字符编码是UTF-8,仍然出现乱码问题。找了很多解决方案终于了解到:Hibernate自己的字符编码默认不是UTF-8,所以要在hibernate.cfg.xml中的connection.url设置如下内容:
1 | <property name="connection.url">jdbc:mysql://localhost:3306/your_database_name?useUnicode=true&characterEncoding=UTF-8</property> |
设置完成之后,可以正常进行中文操作。